My little MillionDollarHomepage garden
Posted: September 13, 2023
Category:
internet
Back around the time I convinced my family to switch from a 56 kb/s dial-up modem to ADSL, the website milliondollarhomepage.com was launched, and quickly became an Internet phenomenon, selling pixels for advertising space on a 1000x1000 canvas. 18 years later, the homepage is still standing, proudly displaying the Internet billboard of 2005, frozen in time.
Some time ago I bought one of the expired domain names the page points to,
pixels4all.com. In this post I'm exploring this Internet garden.
Pixels for all!
The logo of pixels4all.com is not easy to find. Here's the full image in all its
glory:

Zooming in a bit:
And more:

Here it is, our beautiful yellow and red logo:
![]()
It occupies a real estate of 200 square pixels on the page, or 0.02%, and hence cost $200 to buy in 2005. I didn't buy those pixels myself, but I inherited the ad space when registering the expired domain name years later. It's not exactly prominent on the page, but it is what it is.
Ten dollar copycat
A bit about the previous owners.
The OG pixels4all.com appears to be one of the many MillionDollarHomepage copycats,
surfing on the buzz and offering the same concept or similar. The Internet Archive
gives a few hints
about what used to be there. It was first captured on 2005/12/15, and last on
2006/04/02.

Unfortunately, the banner is pretty much all there is to see. Most pictures are missing,
the Buy Pixels link redirects to a login page, and FAQs is not a link. My best bet
is that pixels could be bought for a limited time of 30 days.
It's also written that 4800 pixels have been sold. This number is consistent across the few months the website was alive, and gives an estimate of the total revenue: $9.6.
From there, starting at the latest in June 2006, the domain is for sale and displays a
Sedo.com parking page,
listing it for $500. Later replaced by
a GoDaddy parking page,
a new
Sedo parking page,
an empty page,
503,
404, and finally in
2017 a redirection to ?reqp=1&reqr=1, an URL which hasn't been archived.
I bought the domain in 2019, and didn't do much with it until 2022, when I set up a dummy page behind a server. I was curious to see if there was any traffic, but more on that later.
My lovely neighbours
So we got a few months of unsuccessful time-based pixel selling in 2006. But enough with failed businesses, let's look at how my neighbours are doing.
Thanks to this MillionDollarHomepage restoration, we can browse the websites directly through the Internet Archive2. My immediate neighbours are pretty cool:
-
Club-Millionaire.com. Pronounced CLUB MILLIONAIRE, and self-described as "for those who believes in endless opportunities of the Universe of the Internet on the Planet of the Earth". It's a kind of Ponzi scheme but also with pixels for the members? Seems legit, but unfortunately it doesn't exist anymore.
-
FairChild.co.uk. With an interesting redirection mechanism (
default.asp->cookie.asp->default.ask?cookies=no), they are "Manufacturers of Industrial Computers And Webservers Since 1989". Nowadays, it times out with a Cloudflare page. -
ETCompany.com. Selling refurbished notebooks, printers and more hardware from the good old days. "Offering WHOLESALE PRICES to the PUBLIC since 1993!!!", but unfortunately in 2023 the domain is for sale, listed at $3695.
-
LaptopBlowout.com. Very similar to the previous one, but with solid deals: "Please, don't spend your efforts and time looking for better prices on laptops. Our prices are the Best on the WEB". Today the page looks empty but triggers ad-blockers and CORS warnings.
-
AWebApart.com. A landing page for a future website builder. They were all the rage back then! Neat, it still exists. It's my only surviving direct neighbour, and I certainly enjoy its company.
Wandering a few hundreds of pixels away, some more distant but notable neighbours are a trip down nostalgia lane. Check out DesignForward.net (it has an intro! a website with an animated intro!), AdvancedInfoStorage.com (with a stand-by page redirecting to https before it was cool), Game.sc (Flash games!), and TheDogWeb.co.uk (nothing less than designer accessories and jewellery for dogs).
Bot traffic
The web changed since 2005, and it's now populated by bots.
I setup a basic index.html behind a web server answering to pixels4all.com, and
collected a year of http logs. There were 86847 http requests made between 2022-08-08
and 2023-08-08, which is small traffic for modern standards, but nonetheless fun to dive
into - I got curious to find out who's hitting this long dead pixel-selling website.
Unsurprisingly, a fair share of bots and scrapers.
Visits per day
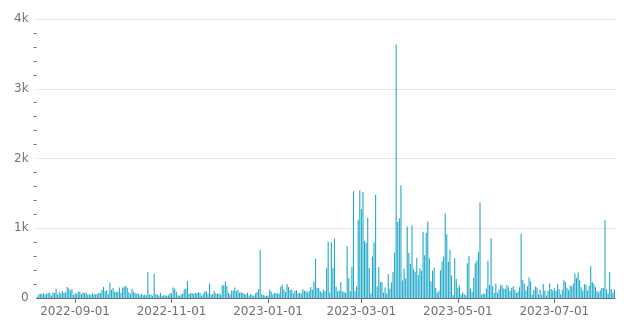
The 23rd of March stands out. 90% of traffic came from the same IP address, located in
Singapore and belonging to the cloud provider Digital Ocean. Interestingly enough, while
that address has tried various well-known URL paths for vulnerabilities before and after
that day, the 3274 requests made the 23rd of March were all for /.
To gather more random stats, I included an image of a
web legend in the index.html served by
pixels4all.com. The URL for that image can be found in the HTML source code.
/rick.jpg was hit… 97 times! Parsing HTML and downloading images is rather costly - so
bots scanning for vulnerabilities don't bother with that (but why whould they).
Where do they come from?
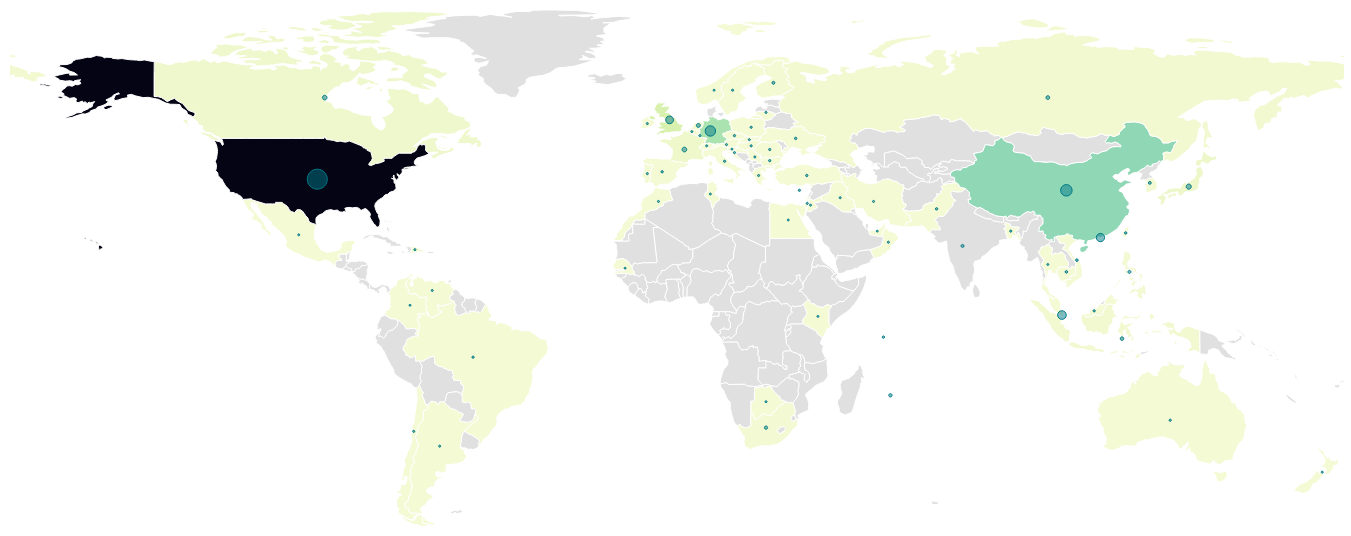
Mapping incoming IP addresses to their associated country3 gives a rough idea of where they geographically come from. #1 on the chart is the USA with 42k queries, #2 is China with 12k queries, and #3 Germany with 9k queries. There are 71 different countries with at least 1 hit.
Of course, this doesn't say much: web crawling software runs in datacenters and probably behind VPNs, not necessarily close to the actual users.
To figure out how someone reached a web page, it can be interesting to look at the
Referer http header, which gives information about the previous page that was visited.
However, web browsers will generally not set this header for cross-domain visits (for
privacy concerns), and crawlers don't have a reason to set it either.
However, ~12% of the requests do have a Referer set. Most of them seem to be
handcrafted as they are missing http[s]: www.google.com or yahoo.com (haha).
Others are parseable URLs on the domain pixels4all.com, but they clearly don't exist,
for example http://www.pixels4all.com/utility/convert/data/co. I have no idea how it
ended up there. Finally, there are vulnerability exploits in the form of code injections
in SQL4 or PHP5.
All in all, not much info about where visitors come from. I certainly hope by following the link from the Million Dollar Homepage!
Where do they go?
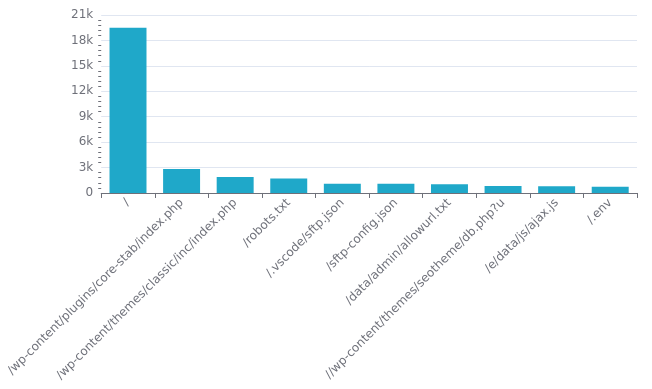
Looking at URL paths, the vast majority of requests are for /. And the rest, well,
clearly comes from lists of vulnerable URLs to probe for, such as files which could
contain credentials or misconfigured WordPress administration pages.
Naturally, they all return 404 for my placeholder website. I wonder how fun it'd be to build a honeypot there by returning fake pages?
Mozlila Firefox
The last bit of useless information can be found in the User-Agent http header. A user
agent is a string identifying the software making the http request, for example
Internet Explorer or curl.
However, back in the day, web servers were serving different content to different
browsers, due to some features (for example <frame>) not being available everywhere,
and they were interpreting the user agent string for that purpose. Browsers didn't want
to be left behind after implementing such features, so they all started to identify as a
variation of Mozilla. For compatibility reasons, pretty much every browser nowadays
identifies itself as Mozilla/5.0 something something.
So do web crawlers and bots, which are spoofing well-known user agents (for example Google Chrome's) to fly under the radar.
That being said, almost 12k requests came with this user agent:
Mozlila/5.0 (Linux; Android 7.0; SM-G892A Bulid/NRD90M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/60.0.3112.107 Moblie Safari/537.36
Notice the typos? Mozlila, Bulid, Moblie. Bots using this are not exactly subtle,
as Mozlila is a
well known typo in rootkits,
which seems to have been copy-pasted in many tools, such as
those developed by Anonymous Fox.
Interestingly enough, some tools have fixed the typo in Moblie but not in Mozlila.
Million dollar garden
It's been fun to dive into the history of a website pretty much nobody ever knew, and look at the traffic logs despite its dormant state for close to 18 years.
I don't know at this point what I'll do with the domain name - in the meantime it's a nice Internet garden to take care of.
Footnotes
-
That last one is odd to me, and I couldn't figure out the meaning behind those URL parameters, besides this uninformative StackOverflow answer. ↩
-
Read more about it on the author blog. ↩
-
Using data from GeoFeed + Whois + ASN. ↩
-
My favorite is
554fcae493e564ee0dc75bdf2ebf94caads|a:3:{s:2:\"id\";s:3:\"'/*\";s:3:\"num\";s:201:\"*/ union select 1,0x272F2A,3,4,5,6,7,8,0x7b247b24687a6c6c616761275d3b6576616c2f2a2a2fb 286261736536345f6465636f646528275a585a686243676b5831425055315262614870736247466e595 630704f773d3 d2729293b2f2f7d7d,0--\";s:4:\"name\";s:3:\"ads\";}554fcae493e564ee0dc75bdf2ebf94ca, an attack targeted towards ECShop, a full-featured software to operate malls, active in China. Behind an expired SSL certificate, the ECshop homepage is pretty entertaining to visit. The source code is somehow available, and I'm no specialist but it doesn't look like SQL injections are taken seriously. ↩ -
Such as
http://www.pixels4all.com//type.php?template=tag_(){};@unlink(FILE);print_r(xbshell);assert($_POST[1]);{//../rss. ↩